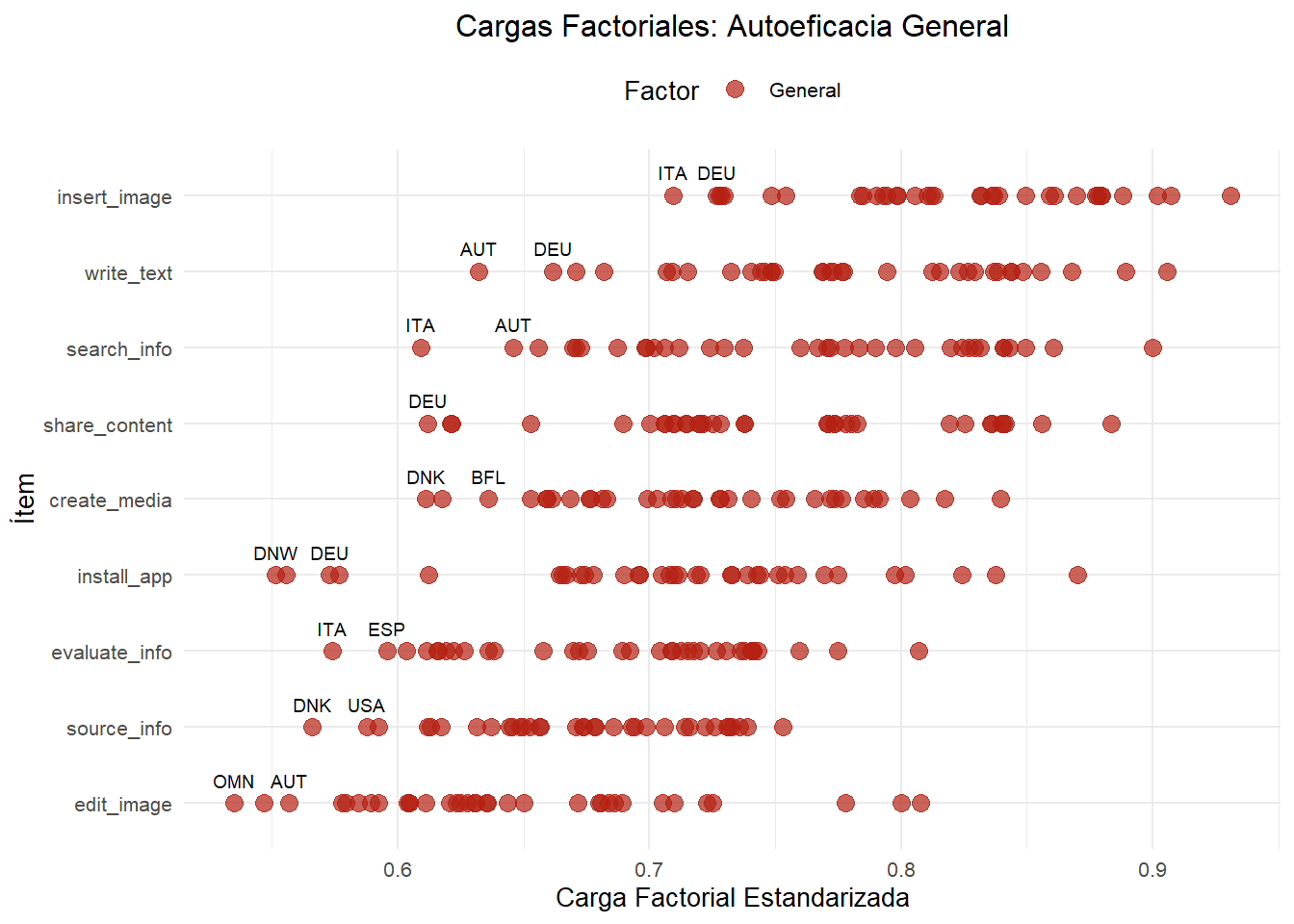
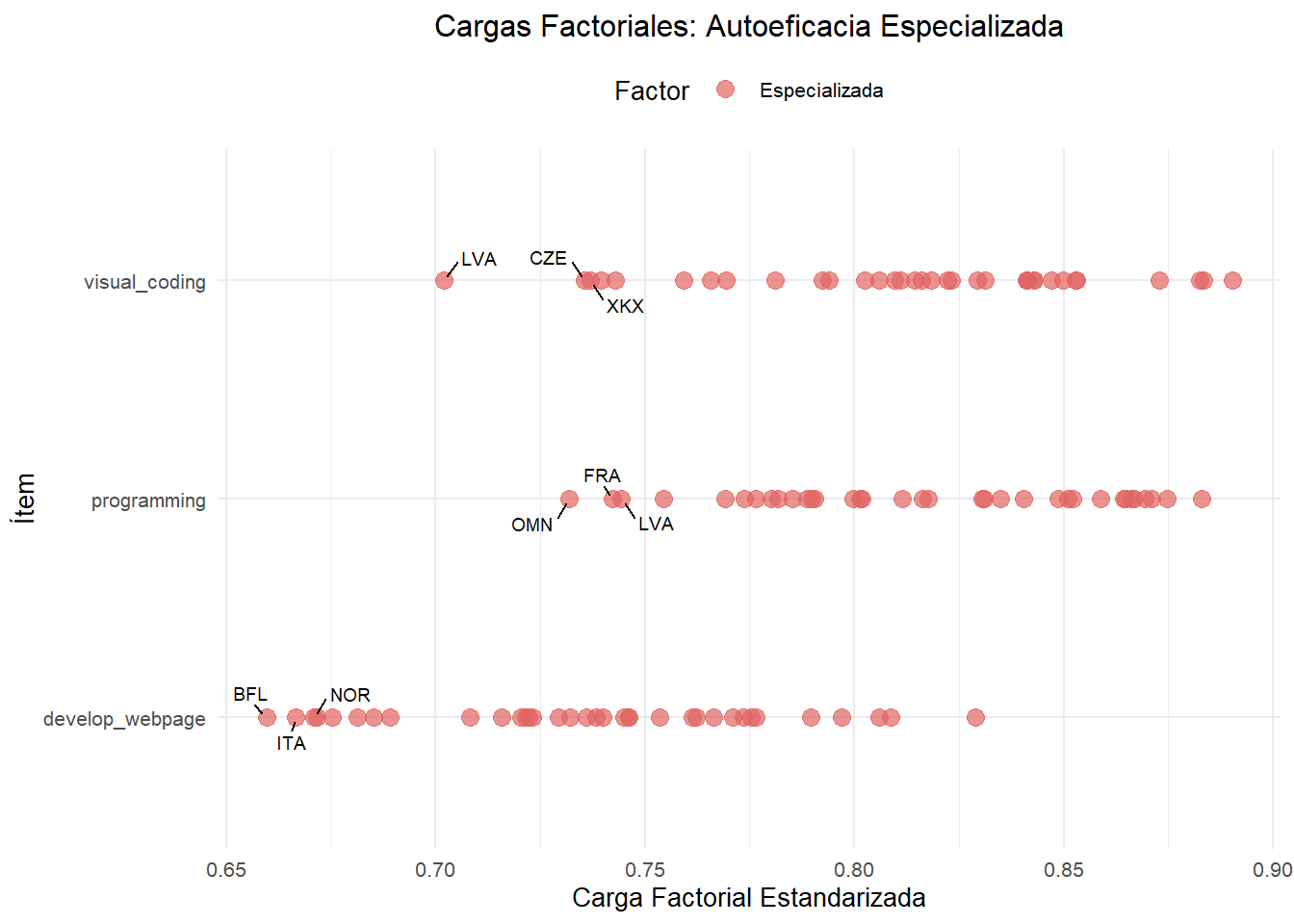
The model is estimated, discarding the Safety (change_settings) and Problem solving (no items) dimensions of DigComp. Also, “Install app” was discarded because in PISA is not measured something similar (Collect and record data is in the same competence, but it is not the same task).
The CFI and TLI are excellent, indicating your model captures the latent structure well. However, the RMSEA and SRMR are high, suggesting possible model misfit or issues like item heterogeneity, correlated residuals, or threshold misspecification.
All loadings are strong (> 0.70) and highly significant (p < .001), meaning your items are good indicators of the latent constructs.
Moderate positive correlation between the two factors → related but distinct constructs.
✅ Factor structure is solid: loadings are strong, and two meaningful factors emerge. ✅ Good global fit: CFI and TLI > 0.95. ❌ Local fit concerns: RMSEA and SRMR suggest further model refinement (e.g., check residuals, thresholds, or item wording). 📊 Large sample size amplifies chi-square sensitivity—so don’t overinterpret it alone.