El índice educacional 2024 fue confeccionado a partir de los datos del SIMCE 2023, contemplando los resultados de la batería de adopción digital en estudiantes de 4to básico y II° medio, y de los profesores de lenguaje y matemáticas. La base contempla más de 400.000 estudiantes y más de 20.000 profesores repartidos en más de 7.000 escuelas. Debido a los casos perdidos, 44 comunas no tenían información, por lo que se tuvo que trabajar con 301 comunas.
Para el índice educacional 2025 se trabajó con los datos de SIMCE 2024. Sin embargo, la batería de adopción digital no estaba disponible en estudiantes (A lo más algunas preguntas de violencia y uso del celular), solo en profesores. En este caso se trabajó solo con profesores de básica y media. La base inicial contempla 25517 casos de profesores y 7710 escuelas.
La batería de adopción digital usada cuenta con un buen alpha (0.85), sin embargo hay un 41% de profesores que no contestan la pregunta.
Código
tab_itemscale(items)
Component 1
Row
Missings
Mean
SD
Skew
Item Difficulty
Item Discrimination
α if deleted
El establecimiento entrega capacitaciones a sus funcionarios(as) para mejorar habilidades computacionales.
41.48 %
2.41
0.97
0.19
0.60
0.59
0.84
Las y los profesionales del establecimiento se apoyan entre sí en caso de tener problemas asociados a la tecnología.
41.38 %
3.37
0.72
-0.88
0.84
0.54
0.84
El establecimiento se preocupa de que haya alguien a cargo de las herramientas tecnológicas.
41.38 %
3.49
0.77
-1.49
0.87
0.60
0.84
El establecimiento se preocupa constantemente de mejorar la infraestructura tecnológica.
41.56 %
2.93
0.96
-0.42
0.73
0.74
0.81
El establecimiento cuenta con internet rápido.
41.55 %
2.96
0.93
-0.48
0.74
0.59
0.84
El establecimiento cuenta con sala de tecnología equipada con computadores.
41.48 %
3.45
0.77
-1.3
0.86
0.63
0.83
Los computadores pueden ser utilizados por cualquiera que requiera información.
41.80 %
2.96
0.98
-0.52
0.74
0.65
0.83
Mean inter-item-correlation=0.457 · Cronbach's α=0.854
2 El problema de los casos perdidos
Tuvimos que explorar que estaba pasando a nivel de profesores, escuelas y comunas para entender si estos casos perdidos eran aleatorios o no.
2.0.1 Nivel profesores
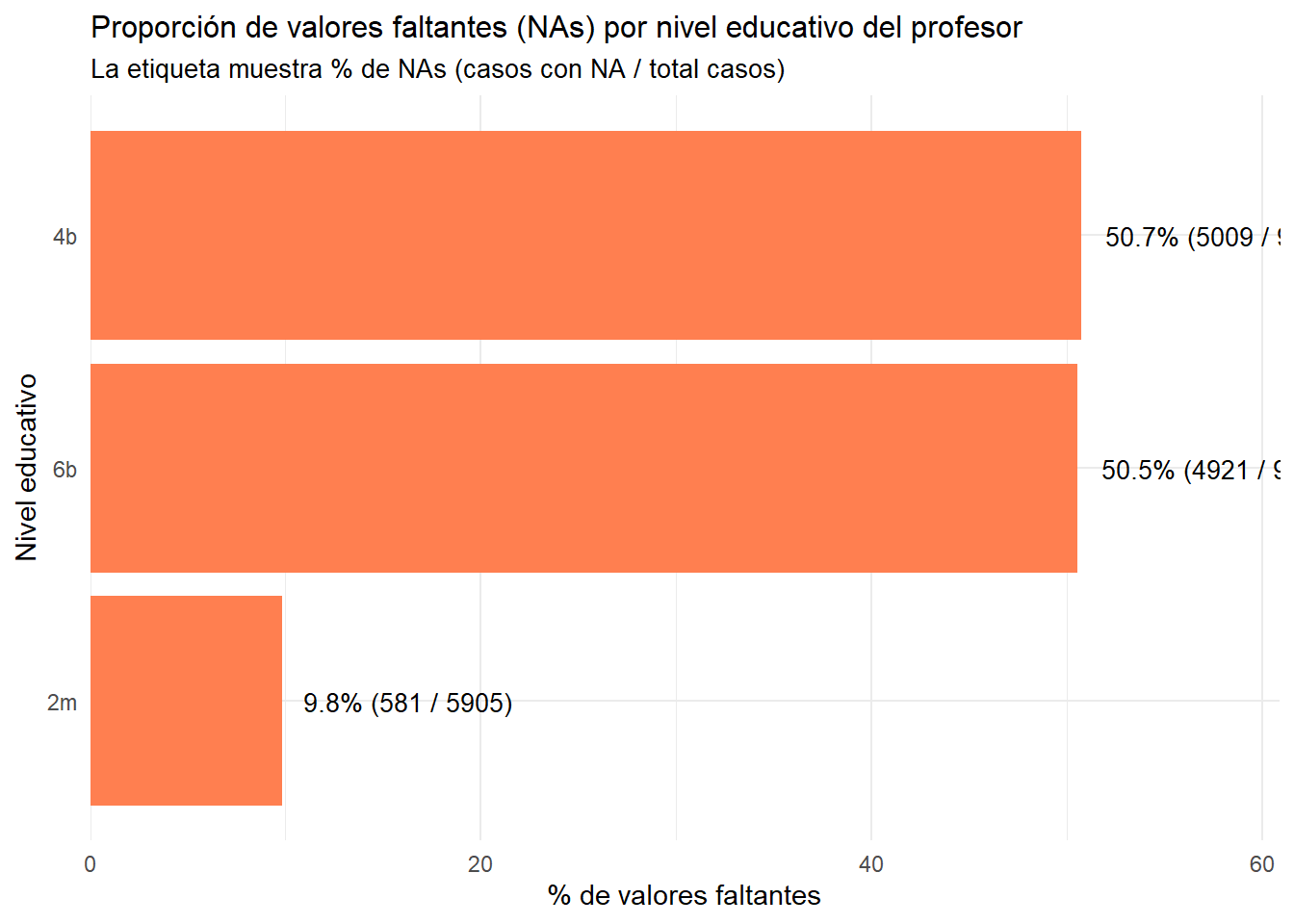
Una vez que se desglosan los profesores con casos perdidos, se nota que se concentran en básica, pero que también hay en media. Por lo que se dictaminó que son aleatorios a nivel de profesores.
Código
stats_nivel_educativo <- docente %>%group_by(p_grado) %>%summarise(n_total =n(),n_NAs =sum(is.na(p_idc)),n_completos =sum(!is.na(p_idc)),prop_NAs = (n_NAs / n_total) *100,prop_completos = (n_completos / n_total) *100,.groups ='drop' ) %>%# Ordenar por proporción de NAsarrange(desc(prop_NAs))ggplot(stats_nivel_educativo, aes(x = prop_NAs, y =fct_reorder(p_grado, prop_NAs))) +geom_bar(stat ="identity", fill ="coral") +geom_text(aes(label =paste0(round(prop_NAs, 1), "% (", n_NAs, " / ", n_total, ")")), hjust =-0.1, size =3.5 ) +labs(title ="Proporción de valores faltantes (NAs) por nivel educativo del profesor",subtitle ="La etiqueta muestra % de NAs (casos con NA / total casos)",x ="% de valores faltantes",y ="Nivel educativo" ) +theme_minimal() +scale_x_continuous(expand =expansion(mult =c(0, 0.2))) +theme(plot.title =element_text(size =12),plot.subtitle =element_text(size =10) )
2.0.2 Nivel escuelas
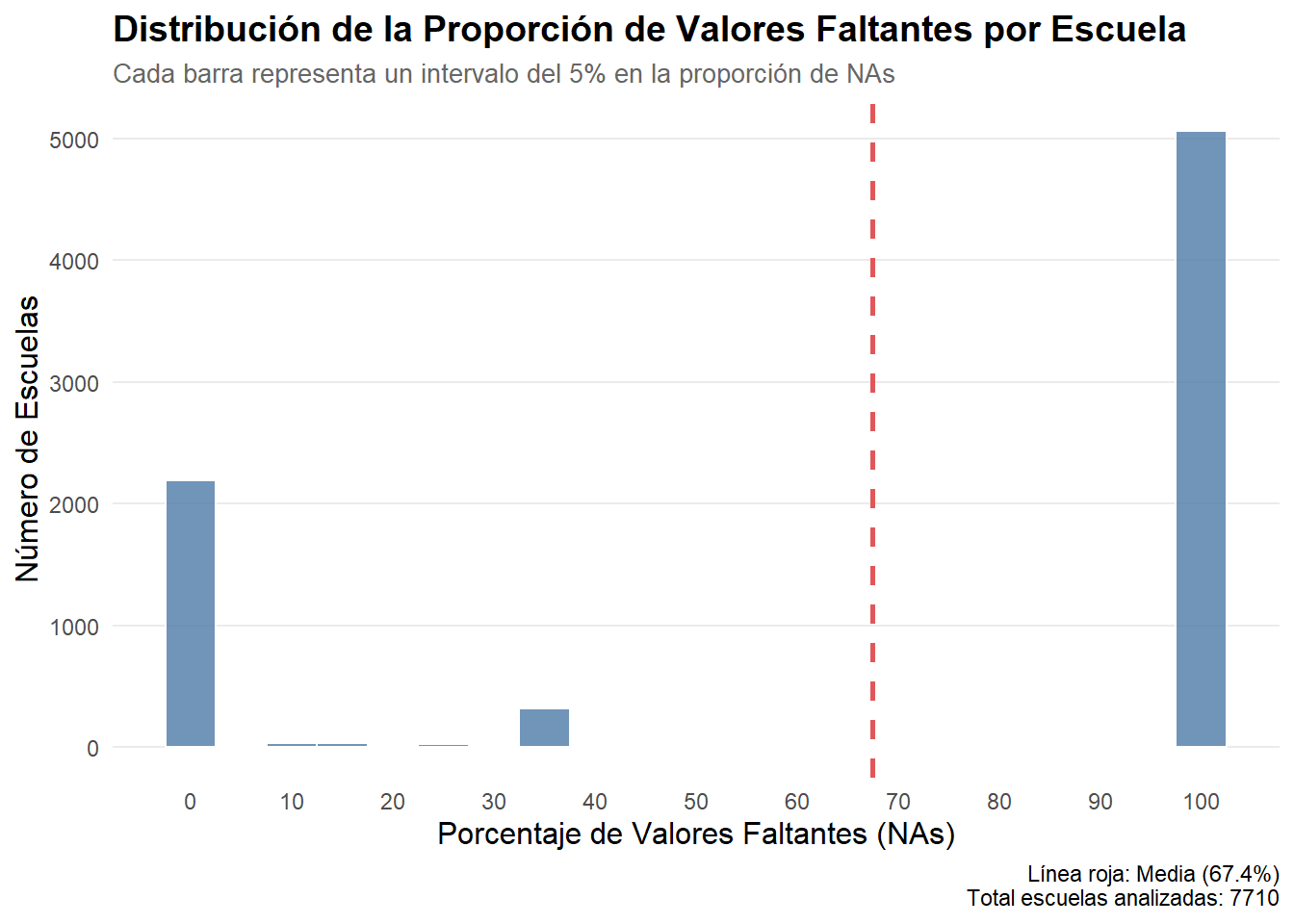
De las 7.000 escuelas analizadas, más de 5.000 de ellas no tienen profesores que responden la batería. A nivel de escuela los datos no son fidedignos.
Código
# 1. Creación variable cantidad de escuelas por comuna (pre limpiar NAs) -------docente <- docente %>%group_by(m_id) %>%mutate(n_escuelas_orig_comuna =n_distinct(c_id)) %>%ungroup()# 2. Creación de variable tipo de escuela# 2. Creación de variable número y porcentaje de NAs por escuela ---------------escuelas_stats_na <- docente %>%# Agrupamos por el identificador único de la escuelagroup_by(c_id) %>%# Calculamos n y % de NAssummarise(c_name =first(c_name), n_escuela =n(),n_NAs_escuela =sum(is.na(p_idc)),.groups ='drop' ) %>%mutate(prop_NAs_escuela = (n_NAs_escuela / n_escuela) *100 ) %>%select(c_id, c_name, n_escuela, n_NAs_escuela, prop_NAs_escuela)escuelas_problematicas <- escuelas_stats_na %>%filter(prop_NAs_escuela >90)# Histograma con estilo profesionalggplot(escuelas_stats_na, aes(x = prop_NAs_escuela)) +geom_histogram(binwidth =5, fill ="#4E79A7", color ="white", alpha =0.8 ) +geom_vline(xintercept =mean(escuelas_stats_na$prop_NAs_escuela, na.rm =TRUE), color ="#E15759", linetype ="dashed", size =1 ) +labs(title ="Distribución de la Proporción de Valores Faltantes por Escuela",subtitle ="Cada barra representa un intervalo del 5% en la proporción de NAs",x ="Porcentaje de Valores Faltantes (NAs)",y ="Número de Escuelas",caption =paste0("Línea roja: Media (", round(mean(escuelas_stats_na$prop_NAs_escuela, na.rm =TRUE), 1), "%)\n","Total escuelas analizadas: ", nrow(escuelas_stats_na)) ) +scale_x_continuous(breaks =seq(0, 100, by =10)) +theme_minimal() +theme(plot.title =element_text(face ="bold", size =14),plot.subtitle =element_text(size =10, color ="gray40"),axis.title =element_text(size =12),panel.grid.minor =element_blank(),panel.grid.major.x =element_blank() )
2.0.3 Nivel comuna
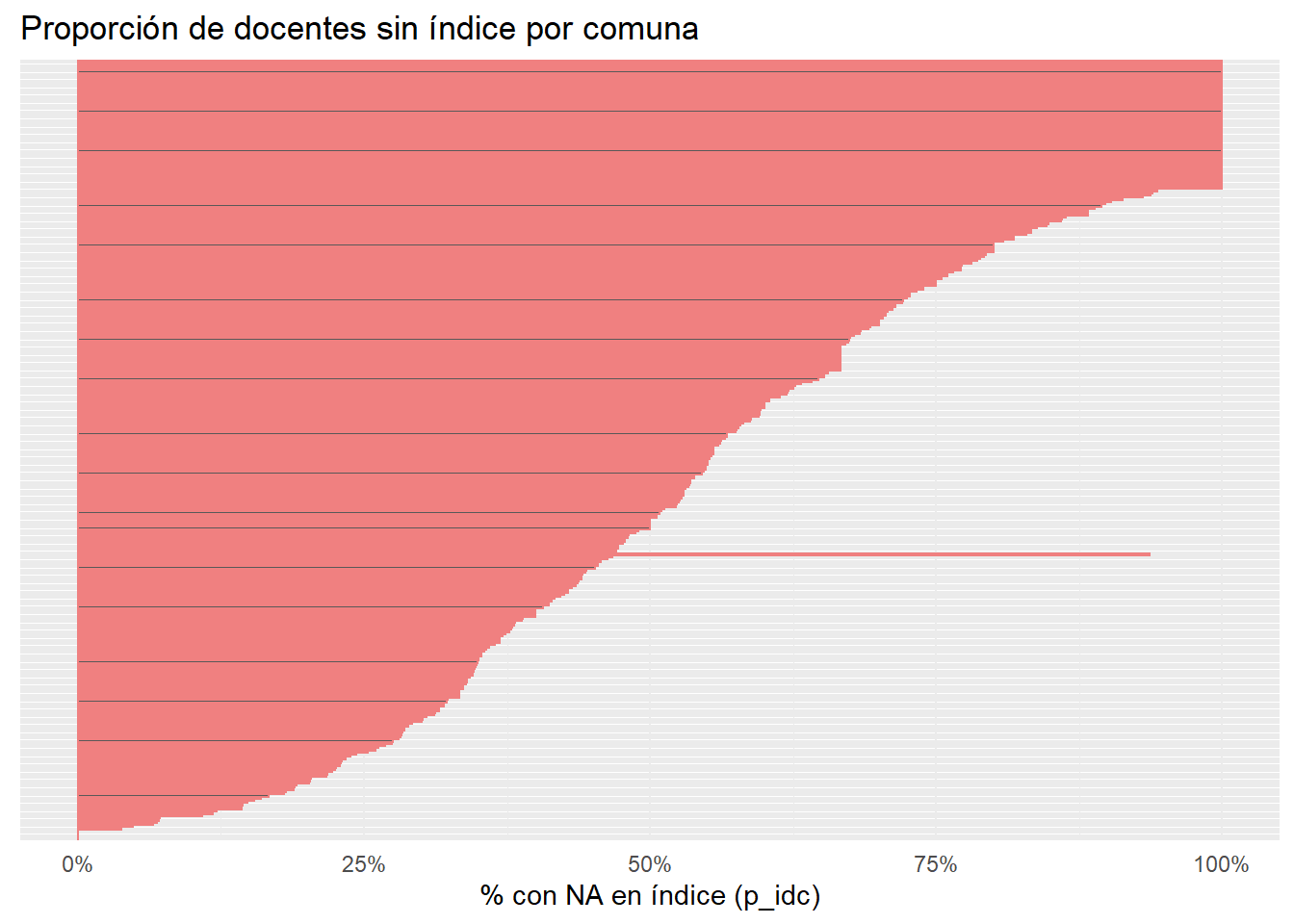
La distribución de profesores por comuna es más pareja. Hay un grupo de comunas con un 100% de profesores con casos perdidos, y luego la proporción va diminuyendo gradualmente.
Código
# Calcular proporción de NA por comunana_por_comuna <- docente |>group_by(m_id, m_name) |>summarise(total_docentes =n(),n_na =sum(is.na(p_idc)),prop_na = n_na / total_docentes,.groups ="drop" ) |>arrange(desc(prop_na))# Filtrar comunas con más de 75% de NAetiquetar <- na_por_comuna# Graficarggplot(na_por_comuna, aes(x =reorder(m_name, prop_na), y = prop_na)) +geom_col(color ="#F08080") +coord_flip() +scale_y_continuous(labels =percent_format(accuracy =1)) +labs(title ="Proporción de docentes sin índice por comuna",x =NULL,y ="% con NA en índice (p_idc)" ) +theme_minimal() +theme(axis.text.y =element_blank())
La base cuenta con un total de 294 comunas con valores en el índice. Con respecto a la muestra del año pasado, hay 36 comunas que se pierden en ambas mediciones, 8 que no estaban y que ahora aparecen, y 15 que sólo están en la muestra anterior.
Código
setwd(here::here())mother_data_2024 <-readRDS("data/proc_data/private_data/2024_mother_data.rds")mother_data_2025 <-readRDS("data/proc_data/private_data/2025_mother_data.rds")indice_2024 <-read_excel("data/proc_data/public_data/2024_idc_v1.xlsx")indice_2025 <-read_excel("data/proc_data/public_data/2025_idc_v1.xlsx")# 2. Comparación de muestra de comunas -----------------------------------------# Seleccionar ID y variable de índice de cada añobase_2024 <- indice_2024 %>%select(id_comuna, c_indice, nombre_comuna) %>%mutate(m_id =as.character(id_comuna)) %>%select(m_id, c_indice, nombre_comuna) %>%rename(indice_2024 = c_indice, m_name = nombre_comuna)base_2025 <- indice_2025 %>%mutate(m_id =as.character(m_id)) %>%select(m_id, m_idc, m_name) %>%rename(indice_2025 = m_idc)# Unir ambas bases por m_idcomparacion <-full_join(base_2024, base_2025, by ="m_id", suffix =c("_2024", "_2025"))# Clasificar según presencia de NAresultado <- comparacion %>%mutate(estado =case_when(is.na(indice_2024) &is.na(indice_2025) ~"NA en ambos años",is.na(indice_2024) &!is.na(indice_2025) ~"NA solo en 2024 (comuna ganada)",!is.na(indice_2024) &is.na(indice_2025) ~"NA solo en 2025 (comuna perdida)",TRUE~"Presente en ambos" ) )# Tabla resumentabla_resumen <- resultado%>% dplyr::count(estado)tabla_resumen|>kable()
estado
n
NA en ambos años
36
NA solo en 2024 (comuna ganada)
8
NA solo en 2025 (comuna perdida)
15
Presente en ambos
286
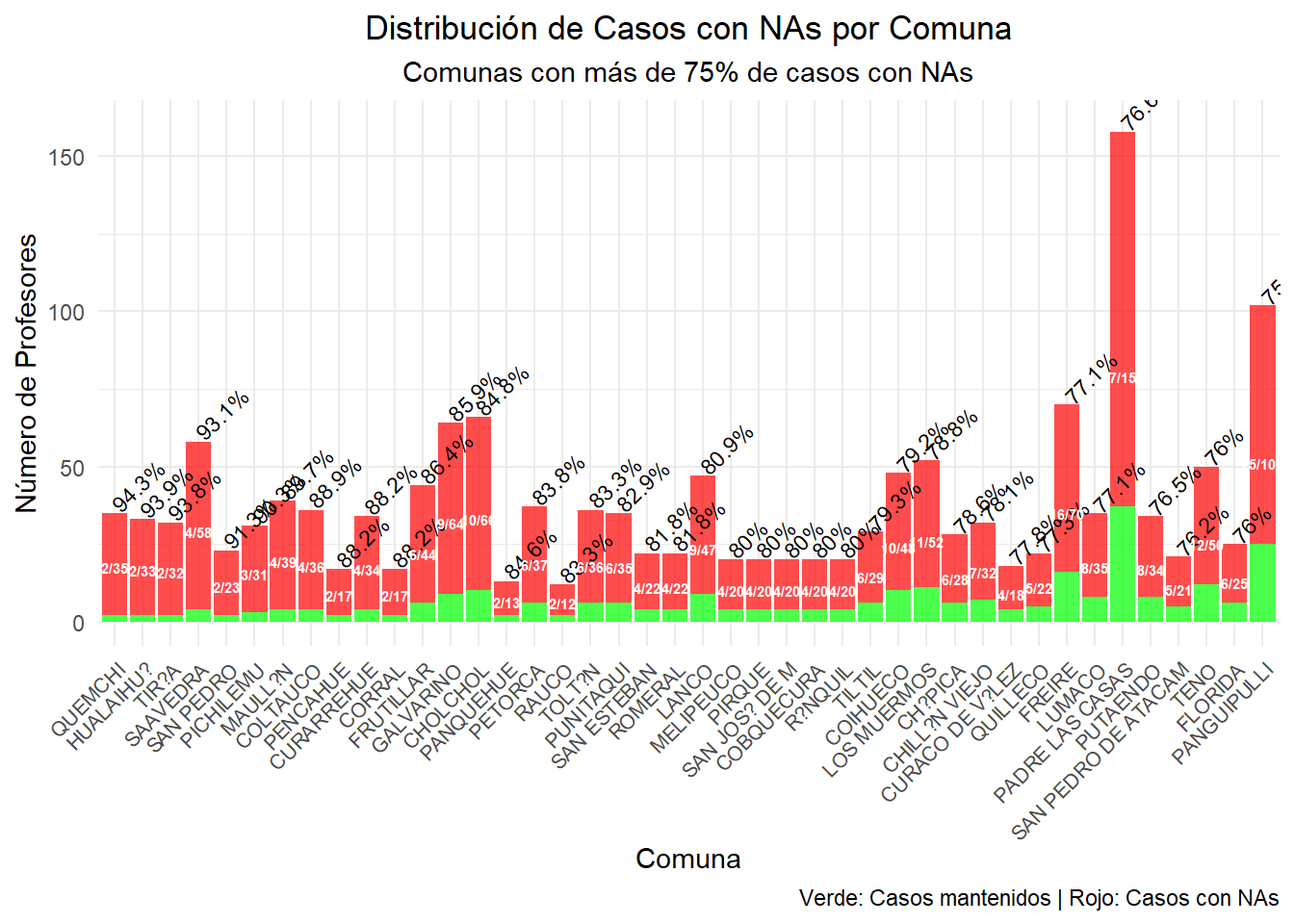
Sin embargo, el gráfico anterior mostraba que hay comunas que llegan a tener hasta con un 95% de casos perdidos. ¿Cuáles son las comunas con muchos casos perdidos? El gráfico las muestra en las etiquetas del eje X. En verde se muestra el n de profesores con valor, en rojo los que tienen NA. Sobre la barra se muestra el porcentaje de profesores con casos perdidos en la comuna.
Código
comunas_stats_NAs <- docente %>%group_by(m_id) %>%summarise(m_name =first(m_name),n_escuelas_orig_comuna =n_distinct(c_id),n_profesores_orig_comuna =n(),n_NAs_comuna =sum(is.na(p_idc)),prop_NAs_comuna = (n_NAs_comuna / n_profesores_orig_comuna) *100,casos_mantenidos = n_profesores_orig_comuna - n_NAs_comuna,etiqueta_prop =paste0(round(prop_NAs_comuna, 1), "%"),etiqueta_fraccion =paste0(casos_mantenidos, "/", n_profesores_orig_comuna),.groups ='drop' ) %>%select(m_id, m_name, n_profesores_orig_comuna, casos_mantenidos, n_NAs_comuna, prop_NAs_comuna, etiqueta_prop, etiqueta_fraccion) %>%arrange(desc(prop_NAs_comuna))library(ggtext)datos_grafico <- comunas_stats_NAs %>%filter(prop_NAs_comuna <100& prop_NAs_comuna >75)grafico_prop_nas <-ggplot(datos_grafico, aes(x =reorder(factor(m_id), -prop_NAs_comuna))) +# Barra verde para casos mantenidosgeom_col(aes(y = casos_mantenidos), fill ="green", alpha =0.7) +# Barra roja para casos con NA (apilada encima)geom_col(aes(y = n_NAs_comuna), fill ="red", alpha =0.7, position =position_nudge(y = datos_grafico$casos_mantenidos)) +# Añadir texto con proporción de NAsgeom_text(aes(y = n_profesores_orig_comuna +2, label = etiqueta_prop), size =3, angle =45, hjust =0) +# Añadir texto con fracción de casos mantenidos dentro de la barrageom_text(aes(y = n_profesores_orig_comuna /2, label = etiqueta_fraccion), size =2, angle =0, hjust =0.5, color ="white", fontface ="bold") +# Personalizar ejes y etiquetasscale_x_discrete(labels =setNames(datos_grafico$m_name, datos_grafico$m_id)) +labs(title ="Distribución de Casos con NAs por Comuna",subtitle ="Comunas con más de 75% de casos con NAs",x ="Comuna",y ="Número de Profesores",caption ="Verde: Casos mantenidos | Rojo: Casos con NAs" ) +theme_minimal() +theme(axis.text.x =element_text(angle =45, hjust =1, size =8),plot.title =element_text(hjust =0.5),plot.subtitle =element_text(hjust =0.5),legend.position ="none" )grafico_prop_nas
Con estos datos en mano se debe tomar una decisión. ¿Qué umbral de casos disponibles vamos a definir para darle alguna validez al índice? La siguiente tabla muestra los efectos de cada decisión posible.
Código
umbrales <-c(5, 10, 15, 20, 25)tabla_umbrales <-data.frame(umbral_casos =paste0(umbrales, "%"),numero_casos_mantenidos =sapply(umbrales, function(x) {sum(comunas_stats_NAs$prop_NAs_comuna < (100- x)) }))library(knitr)library(kableExtra)tabla_html <-kable(tabla_umbrales,format ="html",col.names =c("Umbral de Casos", "Número de Casos Mantenidos"),caption ="Comunas mantenidas según umbral de casos válidos")tabla_html
Comunas mantenidas según umbral de casos válidos
Umbral de Casos
Número de Casos Mantenidos
5%
294
10%
288
15%
281
20%
267
25%
249
3 Comportamiento de los puntajes
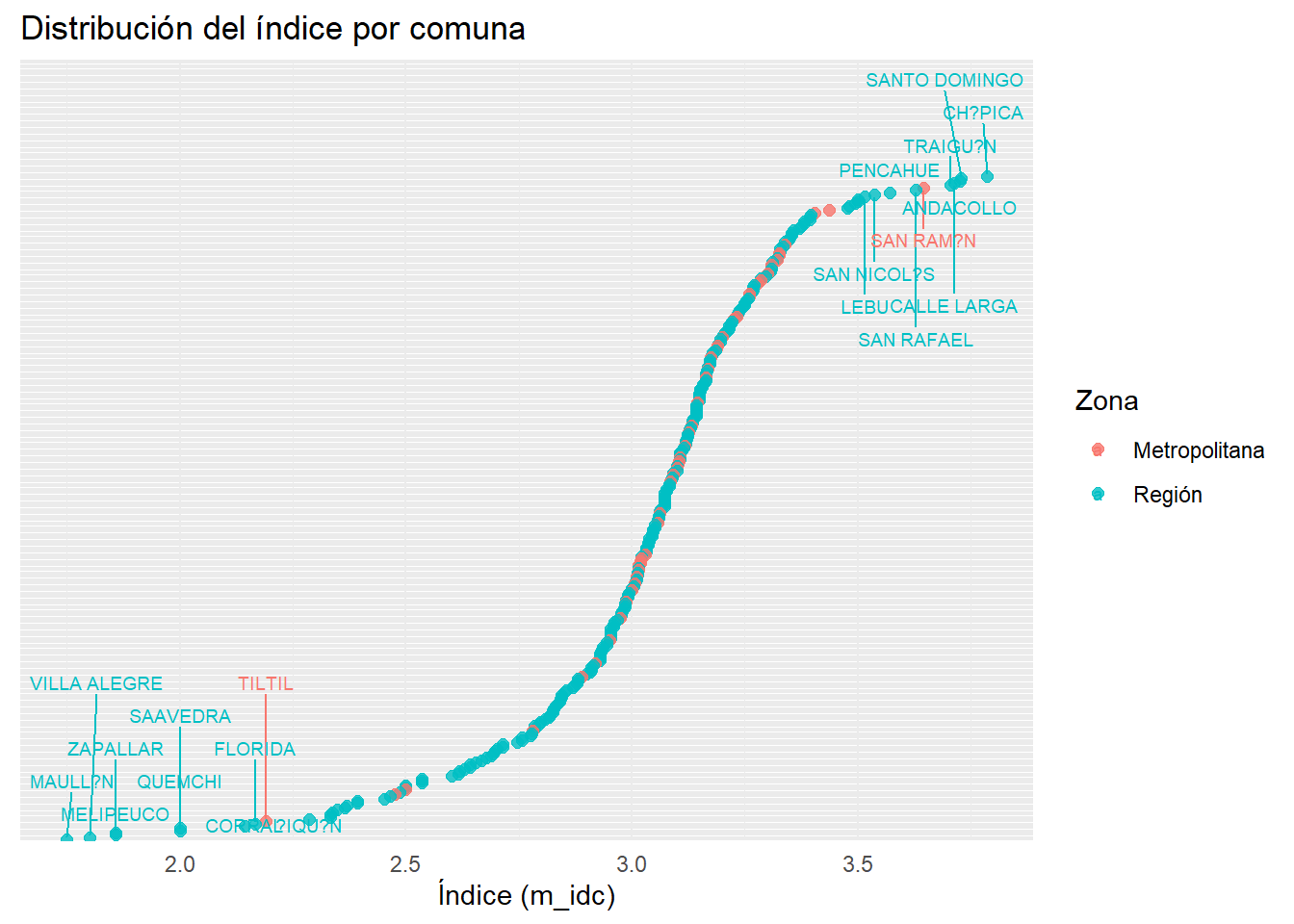
El índice comunal tiene una distribución normal, donde comunas sospechosas ganan en el ranking al igual que el año pasado.
Código
# Añadir variable "rm"idc_rm <- idc %>%mutate(rm =ifelse(r_id ==13, "Metropolitana", "Región"))# Usar la misma base para top_bottomtop_bottom <- idc_rm %>%arrange(desc(m_idc)) %>%slice_head(n =10) %>%bind_rows( idc_rm %>%arrange(m_idc) %>%slice_head(n =10) )# Plotggplot(idc_rm, aes(x = m_idc, y =reorder(m_name, m_idc), color = rm)) +geom_point(size =2, alpha =0.8) +geom_text_repel(data = top_bottom,aes(label = m_name, color = rm), # <- importante: asegurar que el color esté también en esta capasize =2.5,max.overlaps =50,direction ="y" ) +labs(title ="Distribución del índice por comuna",x ="Índice (m_idc)",y =NULL,color ="Zona" ) +theme_minimal() +theme(axis.text.y =element_blank())
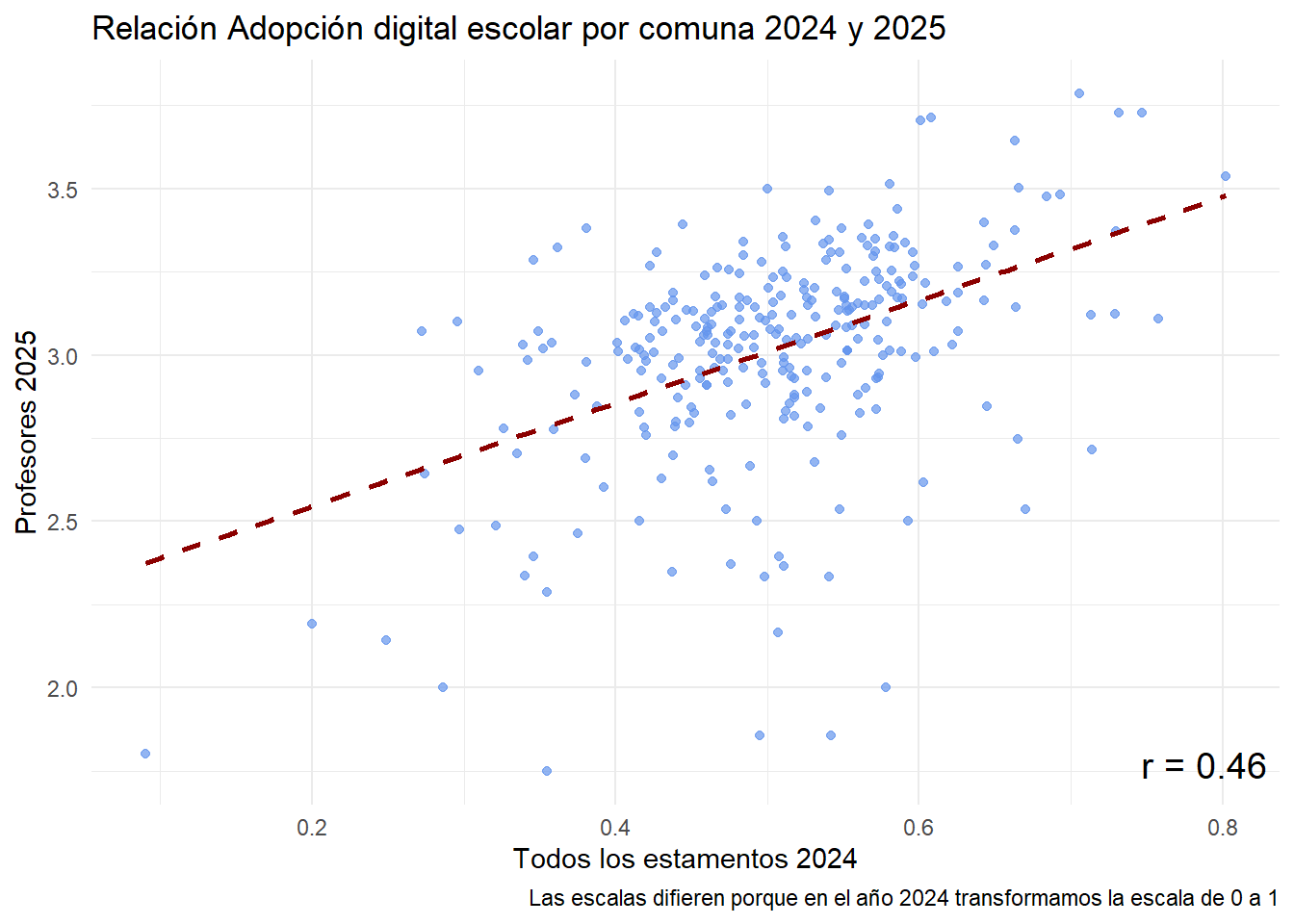
Tiene una correlación de .46 respecto al índice educacional del año pasado. Se parece, pero no del todo.
Código
# Filtrar solo comunas presentes en ambos añosdatos_completos <- resultado %>%filter(!is.na(indice_2024) &!is.na(indice_2025))# Calcular correlaciónr_valor <-cor(datos_completos$indice_2024, datos_completos$indice_2025, use ="complete.obs") %>%round(2)# Graficarggplot(datos_completos, aes(x = indice_2024, y = indice_2025)) +geom_point(color ="#6495ED", alpha =0.7) +geom_smooth(method ="lm", se =FALSE, color ="darkred", linetype ="dashed") +annotate("text", x =Inf, y =-Inf, hjust =1.1, vjust =-1,label =paste0("r = ", r_valor), size =5, color ="black") +labs(x ="Todos los estamentos 2024",y ="Profesores 2025",title ="Relación Adopción digital escolar por comuna 2024 y 2025",caption ="Las escalas difieren porque en el año 2024 transformamos la escala de 0 a 1" ) +theme_minimal()
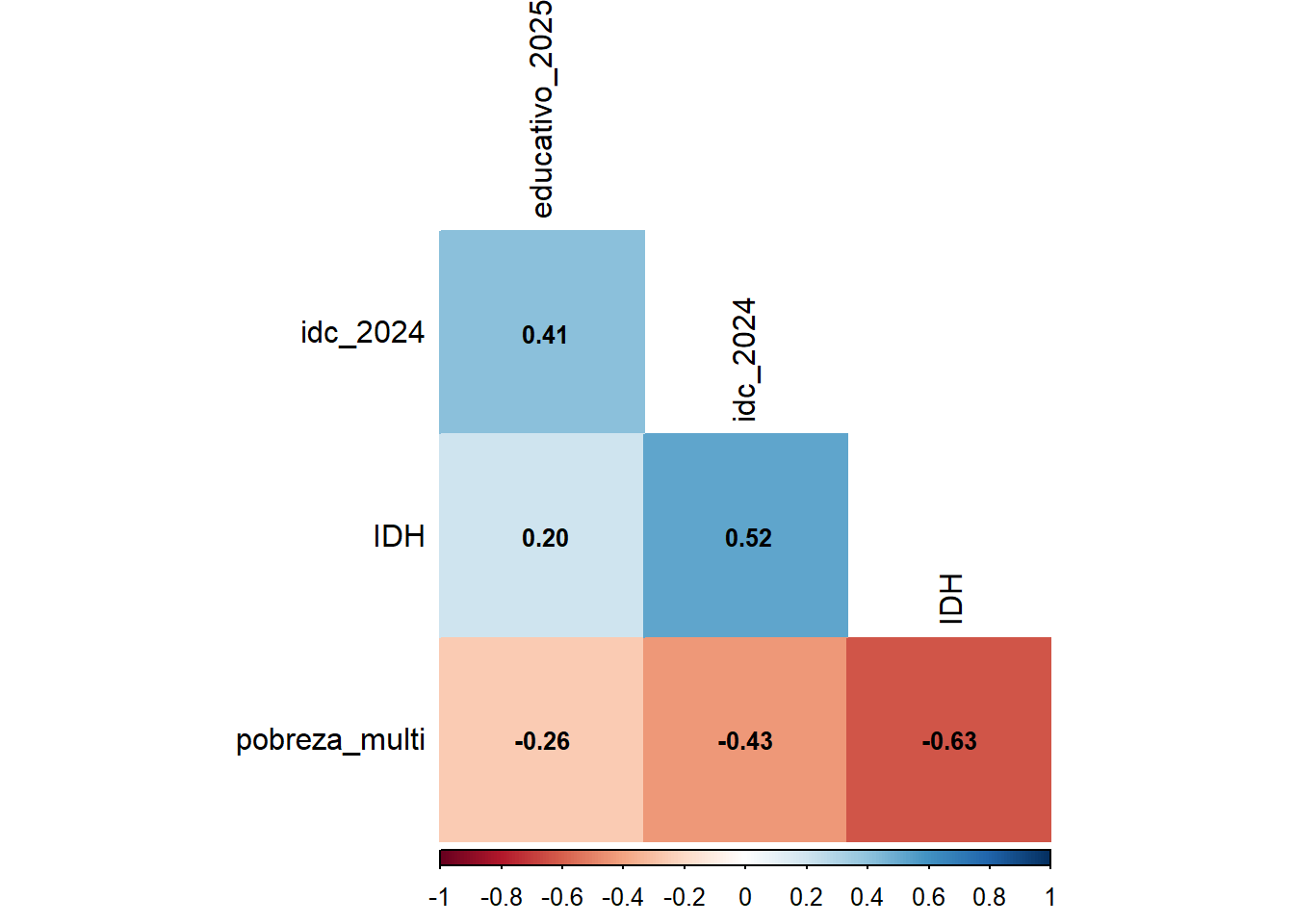
Además, presenta magnitudes más leves respecto a las correlaciones de lo que hallamos el año pasado.
Código
idc_others <-merge(select(idc, m_id, educativo_2025=m_idc), idc_2024, by ="m_id", all.x =TRUE)idc_others <-merge(idc_others, idh_comunal, by ="m_id", all.x =TRUE)idc_others <-merge(idc_others, pobreza_multi_comunal, by ="m_id", all.x =TRUE)idc_others <- idc_others|>select(-m_id)corrplot(rcorr(as.matrix(idc_others))$r, p.mat =rcorr(as.matrix(idc_others))$P, method ='color', type ='lower', insig='blank',tl.col ="black",bg="white",na.label="-",addCoef.col ='black', number.cex =0.8, diag=FALSE,sig.level =0.05)